1344 private links

Tout le monde a déjà utilisé ses fesses pour pondre un bout d’algo. Même toi qui lit ce texte avec des yeux hostiles. L’amoureux des process et le premier artisan développeur de France : ton postérieur à été utilisé dans un programme. D’ailleurs beaucoup de logiciels sont en partie, ou totalement, codés avec le cul. Mais pourquoi ? Qu’est-ce qui fait que, tous ensemble, on s’est bien mis tous d’accord pour faire de la merde ? Allez aujourd’hui on enfile son masque à gaz et on essaye de comprendre les codebases les plus pourries du monde !



Nouvelle release du plugin.
Changelog
Added
- Hide URL parameter for notes (check out the README).
- UT and Travis build
Fixed
- Fix an issue where a field would be cut with a negative number
- Remove non alphanumerical tags because Twitter only allows that
- PSR-2 syntax
Changed
- URL are now removed from title, description and tags to prevent length errors, broken links and unreadable tweets.
- All internal function are now prefixed to avoid collusion with other plugins
thanks to @yomli

kebab-case (bien qu'un peu controversé)
snake_case
https://en.wikipedia.org/wiki/Letter_case#Special_case_styles
https://stackoverflow.com/a/12273101/1484919
The new standard in UI.
Ultralight is the lighter, faster option to integrate HTML UI in your C++ app.Chromium is awesome, it really is. But not for embedders. Over the past 10 years it has become bloated, memory-hungry, and difficult to build much less modify. We needed something in between a huge, all-in-one browser toolkit and a bare-bones HTML UI renderer that only supports a tiny subset of HTML/CSS spec.
Hmm ça peut être pratique pour faire une application desktop légère. Ça nous changerait d'Electron... Par contre je ne sais pas ce que donne le moteur JS dans ce mini SDK. À suivre, de toute façon le projet a l'air un peu jeune et n'a pas encore été porté sur Linux.

Je partage son point de vue, il faut se poser les bonnes questions avant de se lancer dans un refactoring, surtout que le risque d'introduire de nouveaux bugs est important.
J'ajouterais également un autre point qui n'est pas mentionnée : tester unitairement une portion de code « mal écrite ». C'est subjectif, mais on tombe facilement sur du code qui n'est pas testable pour de multiples raisons comme l'usage abusif de variables globales, un énorme pavé de code, etc. Le refactoring peut se faire dans une logique d'améliorer la qualité logicielle en structurant mieux cette portion de code et en la testant. Vous, ou vos futurs collègues vous remercierons plus tard.

Un billet sur la pertinence du code coverage.

Une bibliothèque simple en PHP pour la gestion des adresses IP, avec tout un tas de helpers.
Ça sert toujours, et en plus elle supporte Doctrine.
Une bibliothèque mondiale, contenant tout le code source jamais produit. C'est l'ambition de Software Heritage, dont l'archive est ouverte au public depuis quelques jours. « Après trois ans acharnés à construire l'infrastructure, à collecter les données, à les indexer... on est très contents d'ouvrir les portes de l'archive ! » nous lance le chercheur Roberto Di Cosmo, qui dirige une équipe d'une dizaine de personnes, dont six à plein temps.
NextInpact
Une grande base de données de code source, avec l'ambition de devenir l'Internet Archive du code et ne plus rien perdre.
Un beau projet, soutenu notamment par Microsoft.
Analyse intéressante. Et je me garde sa matrice de priorité sous le coude.

The super fast color schemes generator!
Create, save and share perfect palettes in seconds!
Empowering designers with beautiful and accessible color palettes based on WCAG Guidelines of text and background contrast ratios.

Speed up feedback loop with Contract tests
Des loaders sympas en CSS uniquement.

Gist résumant les méthodes d'itération des arrays en JS (hors for...of).
EDIT, save:
While attempting to explain JavaScript's reduce method on arrays, conceptually, I came up with the following - hopefully it's helpful; happy to tweak it if anyone has suggestions.
Intro
JavaScript Arrays have lots of built in methods on their prototype. Some of them mutate - ie, they change the underlying array in-place. Luckily, most of them do not - they instead return an entirely distinct array. Since arrays are conceptually a contiguous list of items, it helps code clarity and maintainability a lot to be able to operate on them in a "functional" way. (I'll also insist on referring to an array as a "list" - although in some languages, List is a native data type, in JS and this post, I'm referring to the concept. Everywhere I use the word "list" you can assume I'm talking about a JS Array) This means, to perform a single operation on the list as a whole ("atomically"), and to return a new list - thus making it much simpler to think about both the old list and the new one, what they contain, and what happened during the operation.
Below are some of the methods that iterate - in other words, that operate on the entire list, one item at a time. When you call them, you provide a callback function - a single function that expects to operate on one item at a time. Based on the Array method you've chosen, the callback gets specific arguments, and may be expected to return a certain kind of value - and (except for forEach) the return value determines the final return value of the overarching array operation. Although most of the methods are guaranteed to execute for each item in the array - for all of them - some of the methods can stop iterating partway through; when applicable, this is indicated below.
All array methods iterate in what is traditionally called "left to right" - more accurately (and less ethnocentrically) from index 0, to index length - 1 - also called "start" to "end". reduceRight is an exception in that it iterates in reverse - from end to start.
forEach:
- callback answers: here’s an item. do something nutty with it, i don't care what.
- callback gets these arguments:
item,index,list - final return value: nothing - in other words,
undefined - example use case:
[1, 2, 3].forEach(function (item, index) {
console.log(item, index);
});map:
- callback answers: here’s an item. what should i put in the new list in its place?
- callback gets these arguments:
item,index,list - final return value: list of new items
- example use case:
const three = [1, 2, 3];
const doubled = three.map(function (item) {
return item * 2;
});
console.log(three === doubled, doubled); // false, [2, 4, 6]filter:
- callback is a predicate - it should return a truthy or falsy value
- callback answers: should i keep this item?
- callback gets these arguments:
item,index,list - final return value: list of kept items
- example use case:
const ints = [1, 2, 3];
const evens = ints.filter(function (item) {
return item % 2 === 0;
});
console.log(ints === evens, evens); // false, [2]reduce:
- callback answers: here’s the result from the previous iteration. what should i pass to the next iteration?
- callback gets these arguments:
result,item,index,list - final return value: result of last iteration
- example use case:
// NOTE: `reduce` and `reduceRight` take an optional "initialValue" argument, after the reducer callback.
// if omitted, it will default to the first item.
const sum = [1, 2, 3].reduce(function (result, item) {
return result + item;
}, 0); // if the `0` is omitted, `1` will be the first `result`, and `2` will be the first `item`reduceRight: (same as reduce, but in reversed order: last-to-first)
some:
- callback is a predicate - it should return a truthy or falsy value
- callback answers: does this item meet your criteria?
- callback gets these arguments:
item,index,list - final return value:
trueafter the first item that meets your criteria, elsefalse - note: stops iterating once it receives a truthy value from your callback.
- example use case:
const hasNegativeNumbers = [1, 2, 3, -1, 4].some(function (item) {
return item < 0;
});
console.log(hasNegativeNumbers); // trueevery:
- callback is a predicate - it should return a truthy or falsy value
- callback answers: does this item meet your criteria?
- callback gets these arguments:
item,index,list - final return value:
falseafter the first item that failed to meet your criteria, elsetrue - note: stops iterating once it receives a falsy value from your callback.
- example use case:
const allPositiveNumbers = [1, 2, 3].every(function (item) {
return item > 0;
});
console.log(allPositiveNumbers); // truefind:
- callback is a predicate - it should return a truthy or falsy value
- callback answers: is this item what you’re looking for?
- callback gets these arguments:
item,index,list - final return value: the item you’re looking for, or undefined
- note: stops iterating once it receives a truthy value from your callback.
- example use case:
const objects = [{ id: 'a' }, { id: 'b' }, { id: 'c' }];
const found = objects.find(function (item) {
return item.id === 'b';
});
console.log(found === objects[1]); // truefindIndex:
- callback is a predicate - it should return a truthy or falsy value
- callback answers: is this item what you’re looking for?
- callback gets these arguments:
item,index,list - final return value: the index of the item you’re looking for, or
-1 - note: stops iterating once it receives a truthy value from your callback.
- example use case:
const objects = [{ id: 'a' }, { id: 'b' }, { id: 'c' }];
const foundIndex = objects.findIndex(function (item) {
return item.id === 'b';
});
console.log(foundIndex === 1); // true
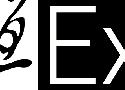
Static analysis tools for PHP
(liste)

Une bibliothèque PHP qui permet de charger le DOM, et propose ensuite une API comprenant les sélecteurs jQuery, les requêtes XPath, etc.
This “props vs. state” question is pretty common for new React devs - they look so similar, but are used differently. So what’s going on there?
J'ai fait une grosse erreur de conception sur un projet sur lequel je bosse actuellement. Je partage donc dans le cas où certains bossent ou ont l'intention de bosser sur une application utilisant OAuth.
J'autorise deux modes d'authentification :
client_credentials: c'est l'application qui s'authentifie avec son ID et sa clé secrète.authorization_code: un peu à la Twitter, c'est l'utilisateur qui autorise le service être attaché à son compte.
Je suis parti du principe que le client était unique, et lui aie rattaché un certain nombre de données utilisateurs. Sauf que dans le cas d'une authentification par authorization_code, tous les utilisateurs utilisant le même client se partagent l'identifiant du client (c'est logique, quand on y pense), et il n'est donc en aucun cas unique pour un utilisateur !
Bingo, revue du modèle de données et quelques jours de réécriture de code.